魑魅魍魉 发布的文章
株洲老房子里面的小人饰品
Nokia 920拍的一些株洲老房子里面的小人饰品,感觉很有意思,不过数量还是少了一些,也不知道放在哪里拍出来好看,就随便来了几张,不过Nokia 920的拍照效果还是一如既往的让我满意。
[gallery ids="427,428,429,430,431,432,433,434,435,436,437,438,439"]
今天给老婆拍的几张照片
使用Nokia 920 给老婆拍的一些照片,感觉这个手机还真不错哈,现在我的Sony Nex-5C已经躺在那里很多年啦,除了专门去拍个什么东西,其它时间基本上都只使用920即可满足我的所有需求,一个好的拍照手机比一台好的手机+一台好的卡片机更爽。
[gallery ids="440,441,442,443,444,445,446,447,448,449,450"]
妈妈今天来长沙
妈妈昨天晚上打电话说今天九点的车来长沙,说是过来看看我一阿姨的女儿在这边待得怎么样,顺便选点衣服,其实我也知道,是因为我才来长沙的,因为我现在的婚姻,现在的状态。谁会想过这样的生活呢?谁又希望自己的儿女过这样的生活呢?
姨老是和我说我和老婆应该好好地谈谈,我也知道,可是老婆一直都在告诉我我们之间没有任何问题了,她现在也过得很好,谁都能看得出来现在是怎么样的,只是自己更清楚一些吧。
两个月没有去株洲看老婆了,以前最喜欢的就是到了周末跑去株洲等两天,周一带着货回长沙,喜欢抱着老婆入睡,第二天早早的起床替老婆去店里,下午回家了牵着老婆的手一起去买些菜,然后给她做一顿自认为很不错的晚饭,晚上和老婆一起看看电视,然后一起上床睡觉,如果可能,还会有属于我们自己的性生活。
老婆会跟我说她想我,即使不这么说,她也会在周五问问我这个周末来株洲吗?会跟我说今天吃了什么买了什么去哪里逛了,会跟我说潘艾现在怎么怎么样了,可是所有的这些都已经不存在了,她告诉我现在过得很好,而我知道的是她现在每天失眠,而我,就不需要说什么了吧,我知道我过得不好。
我这一生唯一在乎的就是自己的感情,除了父母家人的那种纯粹接收的情感,我唯一愿意付出的就是爱情,但是没有人知道我对自己的感情有多珍惜,或许在别人看来我真提一个花心的人,只是我自己一直都知道自己是怎么样的。
我可以跟任何人做任何事情,但是不会做违背自己真爱的事情,如果不喜欢,我会直接说,如果爱,我会努力去维护,只是,恋爱和婚姻的区别在于,恋爱的时候,对方总是会认为还有得选择,而婚姻之后,谁都知道,再一次选择有多么的痛苦,而我,婚姻永远都只会有一次,所以,即使我不爱了,我也会努力重新去爱,何况,我是如此地爱着我的老婆。
我不知道如何去区分女朋友与女性朋友,虽然我知道,前者是爱,后者是喜欢,但是除了我所知道自己喜欢的是谁爱的是谁,我也不知道什么样的事情该做或不该做,什么样的话该说或者什么样的话不该说,我只是很简单的跟着自己的感觉去做了去说了,而结果就是现在这样的吧?
有些事情不需要去解释,尤其是像我这种无法解释的事情,纯粹就是信任了吧,只是我一直都不知道如何去改,但是我一直都在改,而有些时候,承认自己犯的错并不难,难就难在改吧,只是我一直都还没有找到自己应该如何去改,感觉自己就是生病了,所以我现在不交新朋友,尤其是异性朋友,而曾经的朋友,如果失去我绝不会去挽留,我唯一需要的就是一个干干净净的人,不知道什么要干净了。
自己都知道应该怎么办了,只能这么每天把自己折磨着……听说男人的下半身决定了上半身,而我现在也确实是这样了的吧,几乎每个晚上都被现状、性、家庭折磨,而当我每每想到这一切都是自己的原因造成的之后,我又该怎么办呢?除了哭……
开启 WordPress Multi Sites,把所有的WP 站点合并到一个系统里面
我一直就有多个网站存在,而且一直都在更新,以前喜欢玩,所以每个网站的CMS使用的都不一样,现在懒得多了,所以,都转到最方便的WordPress下面了,一直很喜欢Drupal的多站点功能,但是Drupal使用起来还是不如WordPress方便,虽然功能强大得多,不过WordPress已经足够我使用了。
今天把 Cary Agos 下面的所有网站都放到了本博客的系统里面去,也就是开启了本站的多站点功能,然后将以前独立的数据都导入到这一个数据里面,使用同样的程序文件,这样方便升级管理,其实整个过程很简单。
第一步:修改虚拟主机配置文件,将所有需要的域名都添加到该虚拟主机上
我的配置文件如下:
server {
listen 80;
server_name caryagos.com *.caryagos.com;
autoindex on;
root /home/caryagos/websites/caryagos.com/public;
error_log /home/caryagos/websites/caryagos.com/logs/error.log;
access_log /home/caryagos/websites/caryagos.com/logs/access.log;
index index.php index.html index.htm;
location ~ .php$ {
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
location / {
try_files $uri $uri/ @rewrite;
}
location @rewrite {
rewrite ^/(.*)$ /index.php?$args;
}
}第二步:修改WordPress 配置文件
我们需要在 WordPress 文件中添加下面这一行:
/* Multisite */
define('WP_ALLOW_MULTISITE', true);这里再访问后台的话,我们需要先进入插件管理页面以确定所有插件都支持 Multi Site 功能,如果不支持的话,我们需要暂停使用或者看看有没有支持 Multi Site 功能的相关的插件。
第三步:配置网络
这一步很简单,进入 工具 &glt; 配置网络页面,按里面的流程来做即可。其实就是输入网络的名称和管理员邮箱,保存之后,会要求你修改WordPress 配置文件,如我的只需要在配置文件里面添加下面这几行即可:
define('MULTISITE', true);
define('SUBDOMAIN_INSTALL', true);
define('DOMAIN_CURRENT_SITE', 'www.caryagos.com');
define('PATH_CURRENT_SITE', '/');
define('SITE_ID_CURRENT_SITE', 1);
define('BLOG_ID_CURRENT_SITE', 1);做完上面这些步骤之后,需要重新登陆。后台已经有了改变了,原来的后台分为了网络控制面板和站点控制面板,网络控制面板是给网络的管理员使用的,而站点控制面板则是给那一个站点的管理员使用的,现在如果要安装插件,只有管理员能安装,安装之后需要在整个网络中启用,站点管理员才能再启用,站点管理员不能单独安装。
第四步:安装必要的插件
为了达到自己的需求还需要安装一些第三方插件,最主要的一个插件是WordPress MU Domain Mapping,它让我们可以为每一个子站点添加独立的域名,而不只是使用主站点域名的二级域名,访问网络管理控制面板,打开插件安装界面,搜索“WordPress MU Domain Mapping”之后安装即可。
安装WordPress MU Domain Mapping
安装完WordPress MU Domain Mapping插件之后,还需要对其进行一些设置,打开设置标签,可以看到多出了两个设置选项,一个是插件设置,一个是域名管理,根据提示我们可以看到,还需要做一部操作,就是在文件系统中,把sunrise.php这个文件移动到wp-content目录,很简单:
$ cd wp-content $ cp plugins/wordpress-mu-domain-mapping/sunrise.php ./
之后还需要修改WordPress配置文件,加入下面这一行配置:
define('SUNRISE', 'on' );这时已经完成了该插件的安装。
安装导入工具以及其它插件
其它插件都必须要在 Network 控制面板里面安装,这个和我们以前使用的是一样的。
第五步:创建站点,导入数据并绑定域名
创建站点之后,我需要先导入数据,方法很简单,把所有数据从原网站导出,然后导入即可,需要选择下载所有文件至新服务器,导入完成之后,使用二级域名先测试访问一下,但是否所有数据都已经导入成功,如果测试发现所有数据已经导入完成,那么就可以把域名的绑定到新的站点上,然后修改域名的CNAME 至服务器主域名或者A记录至服务器的IP地址即可,等域名生效之后,即可发现网站现在已经转移完成,老网站可以选择性的删除,当然了,配置、主题等等的都需要重新弄了,尤其是主题。
域名绑定完成之后,需要选择一个主域名,所有绑定的域名都将被转向至设定的主域名之上,比如我的 Our Aier 这个网站,你可以访问下面三个地址中的任何一个:
但是最终都会被转向至 http://ouraier.com 这个地址。
Oracle VirtualBox 安装 Windows 老版本系统
我最开始接触的电脑是一台DOS机,那是1992年,妈妈一直都没有正式的工作,因为家里并不富裕但是却有想法,所以,1992年,爸爸给妈妈报了一个电脑学习班,那个时候全县城也只有一家和电脑相关的店子,而电脑的数量则是少得可怜,总共十几台吧,乡里是一台都没有,所以,在我妈妈天才般了从一个从来就不知电脑为何物的农民花了五天时间变成一名优秀的电脑用户之后,家里很快就添了一台DOS机,没错,乡里的第一台电脑,那个时候电话都还是手摇的呢……之后,我成了最小的最早的儿童电脑玩家,之后很多年,我才接触了DOS后的另一个系统——Windows 98,但是后来的发展实在是太快了,它似乎早已被我遗忘,直到某一天,我带着自己的 Macbook Pro 来到某个地方,看到下面这个情景,立马……
 辰溪孝坪医院里一台古老的Windows 98 机器,联想的
辰溪孝坪医院里一台古老的Windows 98 机器,联想的
这让我有一种想回到从前的冲动,今天正好找了一些古老的DOS/WINDOWS 系的操作系统,一个一个装起来玩玩吧。
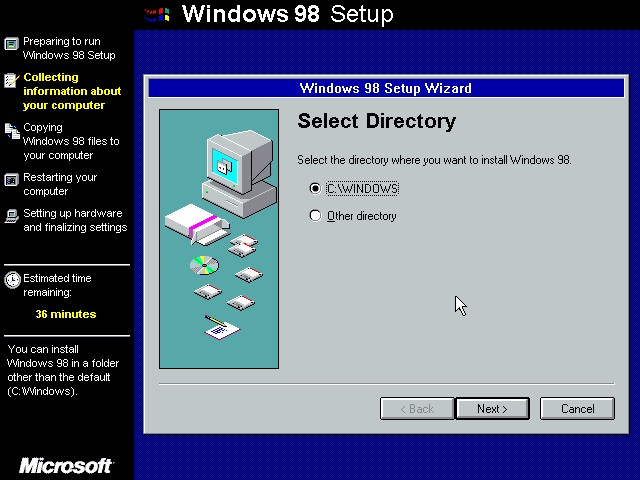
不过说实话,我是第一见到Windows 98 的安装界面,因为以前还没有来得及安装一次Windows 98 系统,我就已经到了 XP 时代,而这 XP 时代却一直持续到现在都还没有退去,当我看到 VirtualBox 推荐的机器配置时,我傻眼了,硬盘容量上面大大的一个 2G 让我顿时无语,2G,如果是放到现在的话,我的一部电影的十分之一都装不下。OK,已经启动了……

这个界面到是很熟悉了,第一次永远还需要做一些配置,不如现在的方便啊,以前从来没有使用 Windows 98 上过网,不过在这上面玩过红色警戒……下面这是Windows 98 的桌面了,有点怀念了没?

使用这个IE来访问 CaryAgos ,那真是悲催了:
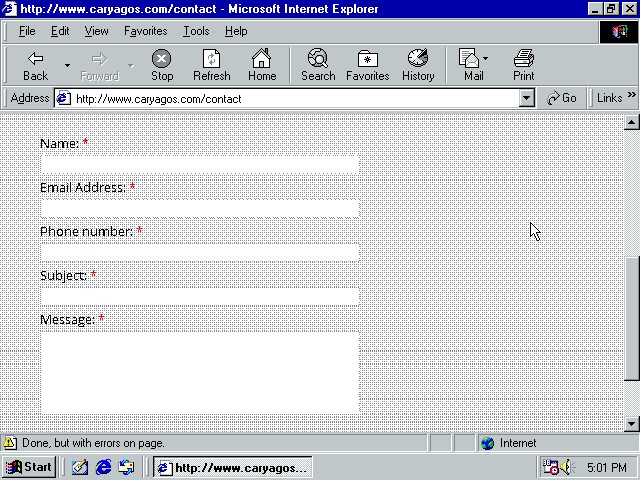
我没有打开首页,因为我的首页内容太多了,打开太慢,而且也根本就没法儿看,从这里我们可以看出来,新技术的发明的本质就是终结老技术……所谓的长江后浪推前浪,前浪死在沙滩上……另外还有一个,C盘在装完了 98 之后,只使用了 282MB,放到现在,我想一个 Windows 系统的核心都止这么点儿吧。
Windows 95 没安装成功,太古老了,好像不像使用ISO能安装的,再找找其它的镜像,另外,3.x 的系统也下载了,只是还不知道怎么使用,先研究研究再说。Windows 98 上面的 Outlook Express 5 居然还可以使用……
从零开始,重新学习,为了自己能正常重启
10年10月离开北京之后,本来是打算正式的告别IT行业的,但是这两年多以来发生了太多,尤其是最近这六个月,已经完全迷失了,任何事情都没有心思做下去,但是好像又每天都在做着规划,只是规划从来没有去执行过,这一个月以来,尝试心平气和的理清这一切,其实结果还是一样的没理清。
以前也有过这样的情况,只是从来没有这么久过,而且也没有这么严重过,以前每一次这样,最后都是同一个办法来解决,那就是一切重来,比如写了一个程序,最后发现有哪里有不太完美的,我就全部从新开始等等的,所以这可能就是这么多年以来我还没有什么建树的原因吧,这也就解释了为什么我到现在还是一无所有,和那些和我一同出社会的人来说,我算是最差的一个了吧。
很多事情放不下,其实放不下的事情本身就不应该放下,尤其当这些事情是属于问题时,永远都不应该放下,而应该是去解决,但是现在却解决不了了,所以,没有工作可做的时候就强制自己重新去学习,新东西是肯定没法学了,我根本就没有心思能安心的接受新事物,所以就把古老的东西一次一次地再重新过一过吧。
其实后来想想,自己无论是工作、学习、爱情、家庭还是什么别的,都是一无所有……
想重新回到以前的那种工作环境,但是我知道,自己已经完全不能适应了,即使是能找得到合适的工作,我也不可能再像以前那样的工作了,我已经不再是从前的那个我,也许一切都已经是事似人非了吧……
全家福
本来今天是要去株洲的,可是某些原因,不可能再去了,我选择了看以前的老照片,然后把所有的我的全家福照片都给翻了出来,有一些年代已经很久远了。
[gallery ids="388,389,390,391,392,393,394,395,396,397,398,399,400"]
变化是什么?人越来越多了,我越来越老了,老人家手上抱的不再是我了……
购买了 Microsoft Office 365的个人版
自从用了Macbook Pro之后,就慢慢地开始使用上了正版软件,并不是OS X 平台下盗版软件不够多(其实比Windows平台下多得多,而且要好得多,个人感觉),最主要还是它有一个 App Store 在那里,买正版的话,太方便了,即使我全新重装系统,一个帐户登陆之后,一个晚上的时间所有的应用都可以还原,如果使用 iCloud 备份的话,还可以连软件的设置都备份下来,如果是Game Center 游戏,游戏进度之类的也都会有,而现在用的PC也慢慢开始有这种趋势了。
以前做文档都是使用的WPS,这是一款很古老的国产文字处理软件了,我是从93年开始使用的,那个时候还是DOS系统,一直使用到现在,先看到了它的发展,对于个人来说的话,我感觉是最好的选择了,我不相信OpenOffice 之类的就一定好,虽然它是开源的,但是开源并不一定代表就适合普通大众使用,而除了这个,我也还真没找到其它的免费的这么好用的文档处理软件了,这次买Office 的正版是因为我太喜欢Microsoft 现在的 Metro 风格了,这种风格是我一直所追求的,简单就是最好的,而且没有让我看着不舒服的圆角(曾经很喜欢,但是看久了,审美疲劳,而不像方角,越看越喜欢),还有一个就是试试曾经不太喜欢的Office 现在成什么样子了,反正第一个月免费。
世界,你好!
这是一个全新的博客,虽然我的博客已经足够的多了,只是有一点太过于私人的话不太想和我的那乱七八糟的各种各样的什么教程、想法之类的文章放在一起,所以就单独开了这个博客,仅仅只是自己生活的日记,也就是说谓的无用的水文吧,虽然我也买了专业的书写笔,还有那么好的墨水,不过还是键盘更加方便。
今天正好也是我婚姻被法律承认两周年纪念,虽然并没有太多可值得庆祝的,甚至还有些许伤感,但是至少也算是熬过两年了,已经一个多月没有去株洲见老婆了,并不是我不想去,而是这大半年来,关系一直在恶化,我已经没有去的理由了。
时间能改变很多,会慢慢淡化过去的伤痛,但是似乎时间同样也淡化了人的情感,也拉开了两人之间的距离,或者本身距离就已经足够的大了,何况这距离还是因为我而产生的,恨并不能表达现在对于自己的情感,但是也很大程度上可以表示一些了吧。
老婆一直在告诉所有人,我们之间已经没有任何问题了,而且现在也一直过得很好了,只是没有问题的我们并不像恩恩爱爱的夫妻,而是陌生人,甚至可以说是害怕在一起的陌生人,我爱老婆,爱这个家,但是自己确实是错了,所以,即使我们的结果是离婚,那也只能怪我一个人。
我无法接受自己如此的生活,并不想如此生活,希望能像一个正常的家庭过着幸福但也艰苦的生活,希望能像别的夫妻那样饭后能手牵手的一起散步,但是这些都只是梦里都不会出现的理想世界里面才会有的,我已经连奢望的勇气都没有了。
我无法把这些跟朋友说,不能和家人说,更不能和老婆说,因为她觉得我们之间已经没有任何需要谈的,我只能一个人每天待在仓库里面,没有心思的啃着美剧,看了这集却已经忘记上一集在讲什么了,想重新拿起自己曾经的那些爱好,可是什么都做不下去,我的所有时间都在想着如何才能和老婆各好如初,但是有些事情并不是一个人的事情,尤其是爱情。
七年之痒我们才走过两年,却已经经历了所有别人要经历的东西,但是我们还会一起走下去吗?
领证两周年
2011年4月12号,和老婆在妈妈的陪同下一起去领了结婚证,从此法律证明了我不再是单身,两年转眼间就过去了,但哪怕只是生命的一瞬间,也让我领会到了人生百态,不再是那个海枯石烂 的少年,而是一个为人父的老年……
相识八年知己,一切都是那么幸福,而婚姻的两年却让两个人从此陌生,都说婚姻是爱情的坟墓,只是没有想过自己也会埋葬在里面,错只错在自己,不怨天不尤人,一切都应该由自己承担,看见自己的婚姻一步一步走向终点,心如刀绞,而唯一剩下的只有我对老婆的爱不变,还有那没日没夜的思念。
[gallery ids="372,375,373,380,376,374,377,378,379,382,381,384"]
我愿又一生换回你的一次欢笑,只是你不再愿意……
株洲的绿色交通——公共自行车
对株洲的好感有很多一部来自于它提供的完善的绿色交通工具——公共自行车,只需要办一张市民卡就可以随时随地取车还车,连效区都有完善的自行车存放架,十分不错,这是去年8月27号没事拍的一些缩影……
[gallery ids="364,365,366,367,368,369"]
此内容被密码保护
我的新手机 Nokia 920 黑色版
自从去年和老婆闹矛盾(原因在我)把iPhone 给摔了之后,虽然后来还是买过一个新的,不过老婆用了不到几天就被偷了,我之后也就一直没有买什么新手机了,电信送了十几部手机,打长株潭都是名话费的,用用也不错了,还有一部Nokia 8830 E,没记错的话是05年的机器,8888元是当时的价格,不过又因为某个类似的原因被我摔了,之后就一直使用送的手机了。
但是送的手机都不能用微信,我自己到是没感觉有什么不妥,只是工作上需要,今年2月份就买了个新手机,Nokia 920,很喜欢黄色版的,但是没货,所以也就只能次之,选了黑色版的,配置看这里:

Nokia 后来出来的那个 Pure View 技术还是不错的,虽然我不知道哪里算用上了,不过照片的质量确实是很不错的,可以看看下面这些我拍的:
[gallery ids="349,350,354,351,352,353"]
其它的到是没有什么说的了,Windows Phone 8 手机,应用不多,有的应用也不是很完美,不过足够我使用了,当然,不能和 Android 或者 iOS 上面的应用比……
[2013/03/11] 长沙湖南省植物园的樱花
[gallery ids="339,341,344,340,342,345,343,338"]
朋友鸟蛋来长沙会老婆,顺便买了个小东西,无事,湖南省植物园一游,其间花未大开,有樱花几朵,翠竹几支,无物,无趣,唯摄取几处小景以为留念,待时日正,重游之……
安装PHP的ZendGuardLoader及 eAccelerator 支持
PHP加速器是一个为了提高PHP执行效率,从而缓存起PHP的操作码,这样PHP后面执行就不用解析转换了,可以直接调用PHP操作码,这样速度上就提高了不少。而如果想要执行通过ZendGuard加密的PHP代码,从PHP5.3以后就需要安装ZendGuardLoader。本文将介绍如何安装ZendGuardLoader及eAccelerator,后者为PHP加速器。如果你还没有一个可用的PHP环境,请阅读《使用 Ubuntu 包管理工具安装与配置Nginx + MySQL/PostgreSQL/SQLite + PHP/Perl/Python 服务器环境》 这篇文章。
安装 ZendGuardLoader
从PHP5.3开始,Zend Optimizer已经不再被支持,而Zend推出了PHP5.3的专用版本,改名为Zend Guard Loader,它的下载地址为:
如果你不想进入它们的主页也可以使用下面这个命令直接下载:
wget http://downloads.zend.com/guard/5.5.0/ZendGuardLoader-php-5.3-linux-glibc23-i386.tar.gz
如果你和我一样使用的是64位版本,则使用下面这行命令:
wget http://downloads.zend.com/guard/5.5.0/ZendGuardLoader-php-5.3-linux-glibc23-x86_64.tar.gz
下载完成之后,解压得到的文件,你会得到一个名为:ZendGuardLoader.so 的文件。
创建一个新的目录,并把 ZendGuardLoader.so 移动到该目录下:
mkdir /usr/zend mv ZendGuardLoader.so /usr/zend
移动完成之后,修改PHP的配置文件,如果你是按《使用 Ubuntu 包管理工具安装与配置Nginx + MySQL/PostgreSQL/SQLite + PHP/Perl/Python 服务器环境》 这篇文章进行的PHP环境配置,那么修改下面这个文件:
/etc/php5/fpm/php.ini
在该文件的最末端添加下面这些配置:
zend_extension=/usr/zend/ZendGuardLoader.so zend_loader.enable=1 zend_loader.disable_licensing=0 zend_loader.obfuscation_level_support=3 zend_loader.license_path=
保存该文件之后,重新启动 php-fpm
/etc/init.d/php5-fpm restart
安装 eAccelerator
最流行的三种PHP加速器有APC、eAccelerator、XCache,XCache是国人的产品,eAccelerator则好像在全球的范围内使用的人数多一些,APC则是PHP PECL中的一个扩展,好像Facebook在使用它,我使用的是eAccelerator,而本文也只介绍如何安装该加速器。
首先下载eAccelerator,它的官方地址为:
或者使用下面这个命令:
wget https://github.com/eaccelerator/eaccelerator/tarball/master mv master eaccelerator.tar.gz
解压该文件,进入解压得到的目录中:
tar zxvf eaccelerator.tar.gz cd eaccelerator-eaccelerator-42067ac/
首先我们复制 control.php 文件到默认虚拟主机的目录下:
cp control.php /srv/www/default/public/eaccelerator-control.php
注意,你解压后得到的目录名称可能与我的不一样,请以你自己的目录名称为准。之后执行下面这些命令:
phpize ./configure make make install make clean
这会在 /usr/lib/php5/20090626/ 目录中生成一个名为 eaccelerator.s 的文件。
现在再一次修改 php.ini 文件,继续在文件的最末端加下面这些配置:
zend_extension="/usr/lib/php5/20090626/eaccelerator.so" eaccelerator.shm_size="16" eaccelerator.cache_dir="/tmp/eaccelerator" eaccelerator.enable="1" eaccelerator.optimizer="1" eaccelerator.check_mtime="1" eaccelerator.debug="0" eaccelerator.filter="" eaccelerator.shm_max="0" eaccelerator.shm_ttl="0" eaccelerator.shm_prune_period="0" eaccelerator.shm_only="0" eaccelerator.compress="1" eaccelerator.compress_level="9" eaccelerator.allowed_admin_path="/srv/www/default/public/eaccelerator-control.php"
保存该文件,再一次重新启动 php-fpm,eAcceleratpr安装成功。
你可以下载 Matrix Stack PHP Prober 探针 来检测是否安装成功。
修改 eAccelerator Control控制文件的用户名与密码
要修改 eAccelerator Control的用户名与密码,只需要打开 control.php(在本文中,将该文件复制为 eaccelerator-control.php文件,所以你应该修改该文件),修改下面这两行即可:
$user = "admin"; $pw = "eAccelerator";
使用 Ubuntu 包管理工具安装与配置Nginx + MySQL/PostgreSQL/SQLite + PHP/Perl/Python 服务器环境
这篇文章的题目是有点儿长,因为我也想不使用什么更简单的话来为本文命名了,所以就使用了最直白的方式。本文将教你如何在一个全新的系统上面安装 Nginx 服务器软件,配置 PHP/Perl/Python 程序的支持以及MySQL/PostgreSQL/SQLite数据库支持,因为服务器的优化是各种各样的,而且一般要去做服务器优化的人应该也不会使用包管理工具来安装这些,所以本文不会对服务器的优化做过多的讨论,仅仅只简单的带过,希望本文对你有帮助。
写在前面的话
你能阅读本文,那肯定是有下面这样的需求中的一个或者多个:
- 刚刚在 Linode 买了一个VPS,选择了Ubuntu作为服务器操作系统,想使用Wordpress/TextPattern或者Drupal建个博客或者网站;
- 公司买了个新服务器,也装了Ubuntu服务器,需要安装一个Plone给公司内部使用
- 像我一样,很喜欢使用Movable Type,我想使用它发布一些静态的网站
- 我是一个SOHOer,有很多个基于PHP开发的客户网站,但是不想再使用共享虚拟主机,想使用自己的服务器集中管理
- ......
其实这些需求可以简单的归为下面这几个:
- 服务器操作系统选择的是 Ubuntu
- 服务器需要能支持 PHP/Python/Perl Web应用
- 服务器需要提供MySQL/PostgreSQL/SQLite 数据库支持
- 服务器应该可以服务于多个网站
- 服务器端的Web服务器软件选择了Nginx而不是Apache
有了需求就只要去努力满足这些需求就成了,本文就是在帮助你知道如何满足这些需求,但是我也不是专业人士,所以,有的时候你可能在别的地方发现有更好的方法,如果你真的找到了更好的方法,请在这里留言告诉我一下,但是请不要在这里来展示你的专业,你就当我这里是放屁就成,但是不要在我这里放屁,否则后果自负。
这篇文章写的时候使用的是 Ubuntu Server 64位 LTS版本,版本号为 12.04,如果你使用的是其它版本,请注意有可能本文里面所使用的命令、参数等需要做一些修改才能适用,最主要的比如那个 /etc/apt/source.list 就肯定是要做修改的,否则肯定会有问题出现。
修改 /etc/apt/source.list 文件并更新与升级系统
我使用的软件源为美国的镜像,它的完整的软件源列表如下:
deb http://us.archive.ubuntu.com/ubuntu/ precise main restricted deb-src http://us.archive.ubuntu.com/ubuntu/ precise main restricted deb http://us.archive.ubuntu.com/ubuntu/ precise-updates main restricted deb-src http://us.archive.ubuntu.com/ubuntu/ precise-updates main restricted deb http://us.archive.ubuntu.com/ubuntu/ precise universe deb-src http://us.archive.ubuntu.com/ubuntu/ precise universe deb http://us.archive.ubuntu.com/ubuntu/ precise-updates universe deb-src http://us.archive.ubuntu.com/ubuntu/ precise-updates universe deb http://us.archive.ubuntu.com/ubuntu/ precise multiverse deb-src http://us.archive.ubuntu.com/ubuntu/ precise multiverse deb http://us.archive.ubuntu.com/ubuntu/ precise-updates multiverse deb-src http://us.archive.ubuntu.com/ubuntu/ precise-updates multiverse deb http://us.archive.ubuntu.com/ubuntu/ precise-backports main restricted universe multiverse deb-src http://us.archive.ubuntu.com/ubuntu/ precise-backports main restricted universe multiverse deb http://security.ubuntu.com/ubuntu precise-security main restricted deb-src http://security.ubuntu.com/ubuntu precise-security main restricted deb http://security.ubuntu.com/ubuntu precise-security universe deb-src http://security.ubuntu.com/ubuntu precise-security universe deb http://security.ubuntu.com/ubuntu precise-security multiverse deb-src http://security.ubuntu.com/ubuntu precise-security multiverse deb http://extras.ubuntu.com/ubuntu precise main deb-src http://extras.ubuntu.com/ubuntu precise main deb http://ppa.launchpad.net/nginx/stable/ubuntu precise main
最后一项为一个 PPA ,我们需要先更新一个密钥,使用下面这行命令:
apt-key adv --keyserver keyserver.Ubuntu.com --recv-keys C300EE8C
这里有一个小地方需要注意一下下,有可能,我是说有可能,你需要更新的Key并不是 C300EE8C 这个结尾的,那么可以先运行 apt-get update ,然后看终端中提示的是什么Key,再根据这个提示运行上面这行命令,把最后的那个参数修改成为提示信息里面的 Key 的最后8位即可。
更新完成Key之后,更新并升级一下:
sudo apt-get update sudo apt-get upgrade
安装 Nginx
安装Nginx 很简单,使用下面这行命令即可:
sudo apt-get install nginx
这会将标准的 Nginx 包安装至服务器,但是使用下面这个命令你会看到其实Ubuntu提供了很多个Nginx版本:
aptitude search nginx
有nginx, nginx-common, nginx-extras, nginx-full, nginx-light, nginx-maxsi, nginx-passenger 等等,如果你有一些特殊的需求,而正好这里面某个版本又提供了你的所有需求,那就选择那个满足你需求的版本吧,否则,就直接安装 nginx 即可,这会安装绝大多数人都用得到的东西到你的系统里面去,不会多也不会少。
安装完成之后,可以使用下面这行命令检测你所安装的Nginx版本:
nginx -v
我安装到的版本是:nginx version: nginx/1.2.4,你的可能与我的不一样,但是如要不一样的话,那应该就是比我更新的版本,没有哪个开发者会把版本号越用越小,你也不会吧,之后使用下面这行命令启动Nginx:
/etc/init.d/nginx start
在上面这个命令中, /etc/init.d/nginx 这个文件就是Nginx的管理脚本,可用的参数有:
- start : 启动Nginx服务器
- stop : 停止Nginx服务器
- restart : 重新启动Nginx服务器
- reload : 重新加载配置文件
- force-reload : 强制重新加载配置文件
- status : 当前Nginx服务器的状态
- configtest : 测试配置文件的正确性(如果你修改了配置文件,重新加载这些配置文件之前,应该先测试一下这些配置文件的正确性,以免因为配置文件的错误而造成服务器的停止,不过像我这种人是从来不这么干的,因为网站停止服务对我来说没啥太大的影响,但是,想想,如果你的网站域名是 taobao.com ,那停止一秒钟的损失有多大?)
除上面说的这个文件还有几个文件与目录你可能需要注意:
- /etc/nginx/sites-available/ :这个目录里面存放的是所有可用的虚拟主机的配置文件
- /etc/nginx/sites-enabled :这个目录里面存放的是指向可用虚拟主机配置文件的软件链接,只有在这里面存放对应的软链接的配置文件才会被Nginx服务器加载
- /etc/nginx/nginx.conf : Nginx 服务器的主配置文件
- /etc/nginx/sites-available/default :默认网站的配置文件,这个是安装的过程中生成的,在本文中,我将修改它。
修改 Nginx 服务器的默认配置文件,创建默认虚拟主机
/etc/nginx/sites-available/default 文件(以下简称“default文件”)是在安装的过程中自动生成的一个配置文件,它定义的一个虚拟主机,但是在我们的使用中,这个虚拟订同没有太大的作用,所有我们会重新写默认虚拟主机的默认文件,它是这样的一个虚拟主机:
- 我们可以通过服务器的IP地址访问到该虚拟主机(默认使用80端口)
- 当我们使用域名访问服务器时,如果该域名没有与某个虚拟主机绑定,那么就表示该的就是这个默认的虚拟主机
- 这个默认的虚拟主机需要支持PHP程序(因为我会把phpMyAdmin这种数据库管理软件放在默认虚拟主机里面),当然这不是必须的,甚至你可以不定义这个虚拟主机都没有关系。
下面我们来满足这些需求;
首先,使用下面这几行命令配置系统自动生成的 default 文件(你可以删除它,但是这个文件也不占用太多的地方,就留着吧,它里面还有很多示例可供你学习呢):
cd /etc/nginx/sites-available/ cp default default.backup
然后清空 default文件,并使用一个你喜欢的编辑器编辑它:
cat /dev/null > default vi default
/etc/nginx/sites-available/default 文件的内容为:
server {
listen 80;
server_name _;
root /srv/www/default/public;
error_log /srv/www/default/logs/error.log;
access_log /srv/www/default/logs/access.log;
}保存该文件,然后创建上面这些配置文件中指定的目录:
mkdir -p /srv/www/default/public mkdir /srv/www/default/logs chown www-data:www-data -R /srv/www/
创建完成之后可以使用下面这行命令来测试一下配置文件是否正确:
/etc/init.d/nginx configtest
如果没有报错,那么使用下面这行命令重新加载配置文件:
/etc/init.d/nginx reload
然后在浏览器中打开 http://your.server.ip.address/ 这个地址即可访问到你的默认虚拟主机,比如我现在是在自己的电脑上面,那么可以使用 http://127.0.0.1 或者 http://localhost/ 访问到该虚拟主机,我在电脑在局域网中的IP地址为 192.168.1.4,所以,使用 http://192.168.1.4 也可以访问到该虚拟主机(局域网中的其它计算机也可以使用这个地址访问你的虚拟主机)。但是你应该发现了,访问这些地址得到的都是同一个结果:
403 Forbidden
这是因为该虚拟主机的根目录中没有索引文件,而且也不允许Nginx自动对目录进行索引,可以使用下面这两种办法来检测一下你的配置是否正确:
创建一个默认的索引文件 index.html
这是推荐的方法,它不会让Nginx自动索引目录中的文件(有些文件你可能并不想让所有访问者都这么轻易的知道),在 /srv/www/default/public/ 目录下创建一个名为 index.html 的文件,输入下面这些内容:
<!DOCTYPE html><html lang="zh-CN"> <head><meta charset="utf-8" /><title>Matrix Stack Index</title></head> <body><h1><a href="http://matrixstack.com/node/139">Matrix Stack</a></h1> </body></html>
保存该文件,再访问上面这些地址,你将看到默认浏览器就会访问到这个文件了。
开启目录的自动索引功能:autoindex
这个文法来得更简单一些,只需要在配置文件里面加上下面这一行即可:
autoindex on;
重新加载Nginx配置文件之后再访问你的服务器地址,即可看到一个页面,它的左上角有一个标题,内容为: Index of * ,这个就是Nginx的Autoindex功能,如果你没有看到这样的一个页面,而是前面上一种方法所创建的那个 *index.html 文件的内容,那是因为当一个目录中存在索引文件时,Nginx会优先使用该索引文件而不是自动对目录进行索引,你只需要删除 index.html 这个文件即可。
关于虚拟主机根目录的设置
虚拟主机的根目录你可以自己选择,我一般并不使用上面这个路径,而是使用 /home/pantao/websites/default/public 这个作为默认,规则是这样的:
- 所有的虚拟主机根目录都为 /home/USERNAME/websites/DOMAIN.NAME/public 目录,其中 USERNAME 表示该虚拟主机所属用户的用户名,DOMAIN.NAME 为该虚拟主机的主域名,它与 /etc/nginx/sites-available/ 中该虚拟主机的配置文件名是一样的。
- 将所有的具有网站的用户的主用户组都设置为 www-data ,Nginx与PHP都是以该身份运行的,所以设置为这个,对于用户来说,文件管理的权限方面有很大的便捷性。
那么按照这种规则的话,如果我的服务器上面有一个名为 huwenxiao 的用户,它的网站主域名为 huwenxiao.com ,那么该网站的路径即为:
/home/huwenxiao/websites/huwenxiao.com/public
同样的,这个网站如果雇用了日志功能,这些日志就保存在
/home/huwenxiao/websites/huwenxiao.com/logs
目录里,public为所有公开访问的文件目录,logs为日志目录,同样的,私有文件目录则可以使用 private(这比如我使用Drupal系统的私有文件系统的话,我一般就会设置私有文件目录为 private 目录),对于像 Elgg 这样的系统的数据文件目录则可以设置为 data等。不过所有这些都只是我个人的喜好,你完全不用去在乎这些,使用你自己感觉最好的就是最好的方法。
安装数据库程序:MySQL/PostgreSQL/SQLite
使用下面这行命令安装这三个数据库系统:
apt-get install mysql-client mysql-server postgresql sqlite3
安装完成之后,对于 MySQL ,我们可以运行一下下面这个命令以提高MySQL数据库的安全性:
mysql_secure_installation
除了修改MySQL root 帐户密码那个没必须修改之外,其它的选项直接一路回车到底即可,也就是一路Yes,对于 PostgreSQL 数据库,我没有使用过,所以也不知道该如何进行下一步的设置,如果你是一个 PostgreSQL 用户,欢迎告诉我安装 PostgreSQL 之后还需要进行哪些操作。
增加 Nginx 对PHP 的支持
现在运行的网站,其程序绝大多数都是基于PHP语言开发的,Nginx支持以fastcgi 的方式对PHP进行支持,首先,使用下面这行命令安装PHP:
apt-get install php5-common php5-dev php5-cgi php5-fpm php-apc php5-mysql php5-pgsql php5-sqlite php5-curl php5-gd php5-idn php-pear php5-mcrypt php5-memcache php5-ming php5-recode php5-tidy php5-xmlrpc php5-xsl
上面这行命令会安装一些最常用的PHP库,包括 MySQL/PostgreSQL/SQLite 的支持,等待安装程序完成之后,可以使用下面这行命令检查安装的PHP版本:
php -v
还需要使用下面这行命令重新启动 php-fpm:
/etc/init.d/php5-fpm restart
为默认虚拟主机提供PHP支持,并且安装phpMyAdmin数据库管理软件
要为某一个Nginx虚拟主机提供PHP支持,需要修改该虚拟主机的配置文件,打开 /etc/nginx/sites-available/default 文件,在它的 server {} 块中添加下面这些代码:
index index.php index.html index.htm;
location ~ .php$ {
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}保存该文件之后还需要重新加载一次该配置文件,使用下面这行命令(以后如果再遇到修改Nginx配置文件的情况,请自行加载,我这里不再重复提示):
/etc/init.d/nginx reload
重新加载之后,可以使用 phpinfo() 函数来查看当前的PHP环境了,在 /srv/www/default/public/ 目录下创建一个名为 phpinfo() 的文件,你可以使用下面这行命令:
echo "<?php phpinfo(); ?>" > /srv/www/default/public/phpinfo.php
这行命令会创建该文件之后,并在该文件中插入 <?php phpinfo(); ?> 这一行代码,现在你可以访问该文件了,如果你在前面的Nginx默认虚拟主机配置中,开启了 autoindex,那么刷新你的浏览器,就会看到,现在网页里面已经列出了该文件,点击该文件即可,如果你没有开启 autoindex,那么请访问 http://your.server.ip.address/phpinfo.php 即可。如果你不想看 phpinfo 信息,那还可以使用PHP服务器探针,这样查看起来可能更简单,本文最下方提供了一个PHP探针的下载地址,你可以将该探针下载并解压至你的虚拟主机目录中,然后访问http://your.server.ip.address/prober.php 即可。
安装 phpMyAdmin MySQL数据库管理工具
phpMyAdmin 是我一直使用的 MySQL 数据库管理工具,它基于 Web ,不像其它一些桌面客户端,它被安装在服务器上,这使得我们可以在任何时候都对 MySQL 进行管理,安装它很简单,只需要从其 官方网站(http://www.phpmyadmin.net/) 下载最新版本的程序包,将其解压至你的虚拟主机目录即可,以本文中的默认虚拟主机为例:
cd /srv/www/default/public wget http://nchc.dl.sourceforge.net/project/phpmyadmin/phpMyAdmin/3.5.5/phpMyAdmin-3.5.5-all-languages.tar.gz tar phpMyAdmin-3.5.5-all-languages.tar.gz mv phpMyAdmin-3.5.5-all-languages phpmyadmin
安装完成之后访问 http://your.server.ip.address/phpmyadmin/ 即可访问 phpMyAdmin ,用户名请使用安装MySQL时设置的 root 帐户及其密码即可。
配置Drupal/WordPress/TextPattern 等常见基于PHP的内容管理系统(CMS)的网址重写
Nginx 有十分强大的网址重写能力,虽然 WordPress 或者 Drupal 等系统都是在Apache上面开发的,官方并没有提供 Nginx 的解决办法,但是我们可以根据 Apache 的网址重写规则很容易的写出 Nginx 版本,在这里,以 Drupal 的网址重写规则为例。
Drupal 的所有请求都是交由 index.php 文件负责的,它接受一个名为 q 的参数,该参数的值为一个 Drupal 路径,比如本文的URL地址为 http://www.matrixstack.com/node/139 ,在该URL地址中, node/139 就是一个 Drupal 路径,它的真实路径应该为: http://www.matrixstack.com/index.php?q=node/139 ,同样的,像本站的介绍页面的 Drupal 路径为about,它在真实路径应该是:http://www.matrixstack.com/index.php?q=about,所以,要让Nginx实现网址重写功能,很简单,只需要把类似 node/139 这样的重写为 index.php?q=node/139 即可,在 default 文件里面添加下面这段配置代码:
location / {
rewrite ^/(.*)$ /index.php?q=$1;
}似乎这样就可以了,但是这样是不行的,还有很多静态文件,它们的路径并不是一个Drupal 路径,而且也不需要Drupal去处理;还有一种情况,比如Drupal 7 的 Image Style功能以及 Drupal 6 中的 Imagecache 等,它们的需求更复杂,当静态文件存在时,直接返回静态文件,不存在是,则由Drupal生成相应的静态文件再返回,下一次请求时直接返回静态文件即可,需求似乎很复杂,但是其实让Nginx来实现这些复杂的需求所需要的网址重写是很简单的一件事情,删除上面的这三行代码,而加入下面这些代码:
location / {
try_files $uri $uri/ @drupal;
}
location @drupal {
rewrite ^/(.*)$ /index.php?q=$1;
}上面这两块代码, location / 部分中 ,try_files 表示,先将请求的URI地址当作文件处理($uri),如果该文件不存在,则再将其当作一个目录处理($uri/),如果该目录也不存在,则当作Drupal路径处理(@drupal),然后在下面的 location @drupal 块中,对 @drupal 路径的进行了定义,即网址重写定义。
写 GO 程序中一些常见的语法和其它错误
很多时候我们都只知道什么样儿的情况下代码会正确的执行,但是却总是记不住怎么样代码会出错,这里列出一些在 Go 开发中最经常看到的一些错误,这让我们在Go报错之前就能知道不去犯这个错,这或许能节省你很多时间。
不必须的导入 (Unncessary Imports)
创建文件 goerror1.go ,并加入下面代码:
package main
import "fmt"
import "os"
func main() {
fmt.Println("Hello World!")
}输出:
# command-line-arguments ./goerror1.go:4: imported and not used: "os"
错误提示为:导入了但是没有使用的包os,为什么?在Go中,你需要使用什么,就导入什么,而导入了什么,就一定要去使用它,否则,就不要导入它,在上面的代码中,你导入了 os 包,但是却没有使用它,所以,它的存在没有任何价值,没有任何价值的东西就不应该存在于你的代码中。
确切的名称——大小写敏感
package main
import "fmt"
func main() {
fmt.println("Hello World!")
}输出:
./goerror2.go:6: cannot refer to unexported name fmt.println ./goerror2.go:6: undefined: fmt.println
你定义的时候使用的是什么名称,那么在使用的使用就必须使用一模一样的名称, p 与 P 是两人个完全不同的东西,看看上面的代码,我们没有定义过 fmt.println,所以,我们不能去调用它,同样的,像下面这样的写法都是错误的:
Package main
Import "fmt"
import "FMT"
Func main() {}
Fmt.Println
fmt.println用分号分开两行代码
如果你是一个有C、C++、Java或者Perl背景的开发者,你可能会注意到了, Go并不要求你在每一行代码结束时插入一个分号,这是因为它会自动的为我们添加(请看[Effective Go]9/articles/effective-go.html)这篇文章的 分号说明部分),但是,有的时候我们却开始烂用这种特性,比如下面这段代码:
package main
import "fmt"
func main() {
fmt.Println("Hello") fmt.Println("World!")
}输出:
./goerror3.go:6: syntax error: unexpected name, expecting semicolon or newline or }
但是下面这样的代码看上去和上面的一模一样,但是却能正确的运行:
package main
import "fmt"
func main() {
fmt.Println("Hello")
fmt.Println("World!")
}输出:
Hello World!
为什么?因为Go不允许你将两行代码写进一行,除非你显示的使用了一个分号来区分这两人行代码,比如我们把上面的代码改成下面这种形式的也是可以正确运行的:
package main
import "fmt"
func main() {
fmt.Println("Hello"); fmt.Println("World!")
}看了我前面翻译的那篇 [Effective Go]9/articles/effective-go.html) 这篇文章的朋友应该也会知道了,为什么上面这段代码能将两行写作一行。
不必要的分号
创建 goerror4.go 文件,写入下面这段代码,再运行它:
package main
import "fmt";;
func main() {
fmt.Print("Hello World!")
}输出:
/goerror4.go:3: empty top-level declaration
在Go中,任何一个分号的出现都表示一个声明的结束,那么,在上面的代码中, import "fmt";; 中的第一个分号是可以接受的,它表示那一个声明的结束,但是在第一个与第二个分号之间不在有任何的声明出现,所以,第二个声明是多余的。
其它一些常见的语法错误
下面这些错误也是很常见的:
package 'main' // 错误,不允许使用引号包裹包名
package "main" // 同上
package main.x // 包名只允许是一个最简单的词汇,不允许使用 "."
package main/x // 同上
import 'fmt' // 需要双引号
import fmt // 需要双引号
func main {} // 需要括号
func main() [] // 需要大括号
func main() { fmt.Println('Hello World!') }
// 错误,需要使用双引号更多关于 Golang 的文章可以访问:
Go 的文件与目录遍历方法 - path/filepath.Walk
Python中有一个函数 os.walk 很好用,不过感觉Go里面同样功能的函数也十分不错,它也叫 Walk ,属于 path/filepath 包里面的函数,它与Python的不同之处在于,Python会是直接遍历所有目录,而Go的版本则是使用一种 “探索者”的模式,该函数本身并不返回什么内容,而是允许你传入自己的函数用来处理每一次遇到文件时的动作。
type WalkFunc func(path string, info os.FileInfo, err error) error
上面这个就是上面所说的“探索者”的函数类型,我们像下面这么使用它:
package main
import (
"fmt"
"os"
"path/filepath"
)
func explorer(path string, info os.FileInfo, err error) error {
if err != nil {
fmt.Printf("ERROR: %v", err)
return err
}
if info.IsDir() {
fmt.Printf("找到目录: %sn", path)
} else {
fmt.Printf("找到文件: %sn", path)
}
return nil
}
func main() {
filepath.Walk("/home/cox/websites/codinuts.csmumu.net/", explorer)
}我们首先定义一下 filepath.WalkFunc 的具体实现,我上面的示例中,我首先判断是不是目录,如果是目录就打印:“找到目录:『目录路径」”,找到文件就打印:“找到文件:「文件路径」“,有错误的话,打印出错误,然后返回错误,如果没有错误,则返回 nil。之后将该函数传送给 filepath.Walk 之后,它将会在每一次遍历到文件时调用该函数,到现在为止,似乎该函数只能让我们打印出找到的内容而已,没有什么实际用处,其实不然,再看下面这个示例:
package main
import (
"os"
"fmt"
"path/filepath"
)
type Walker struct {
directories []string
files []string
}
func main() {
walker := new (Walker)
path := "/home/cox/go/src/github.com/pantao"
filepath.Walk(path, func(path string, info os.FileInfo, err error) error {
if err != nil { return err }
if info.IsDir() {
walker.directories = append(walker.directories, path)
} else {
walker.files = append(walker.files, path)
}
return nil
})
fmt.Printf("找到 %d 个目录以及 %d 个文件n", len(walker.directories), len(walker.files))
}在上面的示例中,我创建了一个新的类型 Walker ,它有两人个字段 directories []string 与 files []string 分别用来保存找到的目录和文件,然后让 WalkFunc 去掉用它,不再直接打印出找到的文件,而是将找到的目录和文件都保存到 walker 的字段里面去,以备以后使用。
这个在我的 Amazon S3 Cograndient 工具里面就使用到了,我使用它来获取本地目录的所有文件。
在Go网络编程中使用外部API——基于 Google API 创建URL地址缩短服务
在本文中,我们将看看如何使用一个来自Go以外的API创建应用,我们将使用Google提供的URL缩短服务API来创建URL地址的缩短版本,你可以在http://goo.gl/体验一把,比如你现在可以通过http://goo.gl/FE6F2 这个地址来访问本文,goo.gl 还会生成一个你的网址的二维码,比如本文的二维码是:
这样的服务是很有用的,比如本文的网址,你应该也看到了,不管是让你记下来或者是让你写下来都太难了,但是缩短之后不管怎么样都简单得多,这么好的服务,Google以API的形式给大家免费使用,你可以在https://developers.google.com/url-shortener/ 了解更多有关该API的信息。
我们要写的程序十分的很简单,同时,我还想在写了这个小程序之后再将它发布到 Google的AppEngine上面去,不过这都是后话了,整个程序需要用到的知识就下面这么几个:
第一步 确定已经正确的创建了开发环境
很简单:
cox@Cox:~/websites$ mkdir urlshortener
cox@Cox:~/websites$ cd urlshortener/
cox@Cox:~/websites/urlshortener$ export GOPATH=$(pwd)
cox@Cox:~/websites/urlshortener$ export PATH=$GOPATH/bin:$PATH
cox@Cox:~/websites/urlshortener$ mkdir pkg bin src第二步 安装APIs
执行下面命令:
go get code.google.com/p/google-api-go-client/urlshortener/v1第三步 在我们的代码中导入该API
上面安装的API可以通过下面这样导入到我们的项目中来了:
import "code.google.com/p/google-api-go-client/urlshortener/v1"完成其它的代码
我的整个代码如下:
package main
import (
"fmt"
"net/http"
"text/template"
"code.google.com/p/google-api-go-client/urlshortener/v1"
)
// 本项目的网页模板
var tmpl = template.Must(template.New("URL Shortener Template").Parse(`
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" /><title>Goo.gl网址缩短服务</title>
<style>
input, button { border: .1em solid #ccc; border-radius: .3em; padding: .5em; }
button { background-color: #f0f0f0; }
button:hover { background-color: #ccc;}
</style>
</head>
<body>
<h1>Goo.gl网址缩短服务</h1>
{{if .}}{{.}}<br /><hr /><br />{{end}}
<form action="/shorten" type="POST">
<label for="long-url">长网址:</label><input type="text" name="url" id="long-url" placeholder="请在这里输入您要缩短的网址" /><button><span>给我短址</span></button>
</form>
<br /><hr /><br />
<form action="/lengthen" type="POST">
<label for="short-url">短网址:</label><input type="text" name="url" id="short-url" placeholder="请在这里输入您要获取原始网址的短网址" /><button><span>给我长址</span></button>
</form></body></html>
`))
func handleRoot(w http.ResponseWriter, r *http.Request) {
tmpl.Execute(w, nil)
}
func handleShorten(w http.ResponseWriter, r *http.Request) {
url := r.FormValue("url") // 获取由网页提交的网址
svc, _ := urlshortener.New(http.DefaultClient) // 使用http中的default client创建一个新的 urlshortener 实例
shorturl, _ := svc.Url.Insert(&urlshortener.Url { LongUrl: url, }).Do() // 填充长的网址然后呼叫缩短服务
tmpl.Execute(w, fmt.Sprintf("<h2 class="url"><a href="%s">%s</a></h2><h3 class="url">源始长网址为:<em>%s</em></h3>", shorturl.Id, shorturl.Id, url))
}
func handleLengthen(w http.ResponseWriter, r *http.Request) {
url := "http://goo.go/" + r.FormValue("url")
svc, _ := urlshortener.New(http.DefaultClient)
longurl, err := svc.Url.Get(url).Do()
if err != nil {
fmt.Println("error: %v", err)
return
}
tmpl.Execute(w, fmt.Sprintf("<h2 class="url"><a href="%s">%s</a></h2><h3 class="url">短网址为:<em>%s</em></h3>", url, url, longurl))
}
func main() {
http.HandleFunc("/", handleRoot)
http.HandleFunc("/shorten", handleShorten)
http.HandleFunc("/lengthen", handleLengthen)
http.ListenAndServe(":8001", nil)
}运行该程序之后您即可以打开浏览器,并访问:
如何基于Go创建数据库驱动的Web应用
本文原文为How to write database-driven Web application using Go的 README.md 文件,如果您想查看本文的原文,请点击前面的英文原文标题,找到该项目的 README.md 文件即可,格式为 *MarkDown*,如果你需要HTML版本的,可能还需要自己安装MarkDown相关的工具,本示例的 Github 地址为:https://github.com/pantao/example-go-wiki/
本文将尝试前着去介绍如何使用 kview/kasia.go 以及 MyMySQL 基于Go语言开发一个小型的简单的数据库驱动的Web应用,就像大家做的一样,我们来开发一个小型的维基系统。
对您个人的要求
- 一些程序开发经验;
- 关于 HTML 与 HTTP 的基础知识;
- 了解MySQL 以及 MySQL 命令行工具的使用;
- 在MySQL中创建数据库;
- 最新的 Go 编译器 - 移步 Go 首页 以了解更多详情。
数据库
让我们从创建应用所使用的数据库开始该项目。
如果你还没有安装MySQL,那么需要你首先安装它,接下来我们会用到它,如果你已经安装了,那么首先我们先来创建该应用数据库。
cox@CoxStation:~$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 120
Server version: 5.5.28-0ubuntu0.12.04.2 (Ubuntu)
Copyright (c) 2000, 2012, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> create database go_wiki;
Query OK, 1 row affected (0.00 sec)
mysql> use go_wiki;
Database changed
mysql> CREATE TABLE articles (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> title VARCHAR(80) NOT NULL,
-> body TEXT NOT NULL
-> ) DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.09 sec)
mysql> exit
Bye到现在为止你已经创建了一个可能使用的数据库,同时还添加了一张表 articles*用来保存我们的维基中的文章数据,你可以在应用中直接使用 *root 帐户连接数据库,当然,更好的办法是创建一个独立的用来测试我们应用用户:
mysql> GRANT SELECT, INSERT, UPDATE, DELETE ON articles TO go_wiki@localhost;
Query OK, 0 rows affected (0.00 sec)
mysql> SET PASSWORD FOR go_wiki@localhost = PASSWORD('go_wiki');
Query OK, 0 rows affected (0.00 sec)现在我们记下刚才所获得的数据:
- 数据库地址:localhost
- 数据库名称:go_wiki
- 数据库用户:go_wiki
- 数据库密码:go_wiki
视图
现在我们开始写点儿 Go 代码了,像以前一样,创建一个工作空间(如果你还不知道如何创建工作空间,请阅读我以前的文章《如何写 Go 程序》),我在这里就简单的将创建的流程所运行的命令复制到这里:
cox@CoxStation:~$ mkdir go_wiki
cox@CoxStation:~$ cd go_wiki
cox@CoxStation:~/go_wiki$ export GOPATH=$HOME/go_wiki
cox@CoxStation:~/go_wiki$ mkdir bin src pkg
cox@CoxStation:~/go_wiki$ export PATH=$PATH:$HOME/go_wiki/bin我所创建的工作空间是:
- HOME: /home/cox
- GOPATH: $HOME/go_wiki
定义应用的视图我使用 kview 以及 kasia.go 这两个包,你应该先安装它们:
cox@CoxStation:~/go_wiki$ go get github.com/ziutek/kview上面的命令会因你的网络不同而需要不同的时间,因为Go需要从网络上下载你所需要的一切东西,所以,请保证你的计算机是已经连网了的,下载完成之后,它会自动的为你安装 kasia.go 和 *kview*。
下一步,在 $GOPATH/src 中创建我们的项目:
在 $GOPATH/src/go_wiki*目录中,创建 *view.go 文件,它的内容如下:
/*
A simple wiki engine based on mysql database and golang.
*/
package main
// 导入 kview
import "github.com/ziutek/kview"
// 声明我们的维基页面视图
var main_view, edit_view kview.View
func init() {
// 加载 layout 模板
layout := kview.New("layout.kt")
// 加载用来展示文章列表的模板
article_list := kview.New("list.kt")
// 创建主页面
main_view = layout.Copy()
main_view.Div("left", article_list)
main_view.Div("right", kview.New("show.kt"))
// 创建编辑页面
edit_view = layout.Copy()
edit_view.Div("left", article_list)
edit_view.Div("right", kview.New("edit.kt"))
}如你所看到的,我们的应用将由两人个页面组成:
- main_view - 用来向用户展示文章内容
- edit_view - 向用户提供创建与编辑功能
任何一个页面又都有两个子栏组成:
- left - 已存在的文章列表
- right - 根据页面不同而展示不同的内容(主页为内容展示,编辑页为编辑表单)
接下来我们来创建第一个 Kasia 模板,它将定义我们网站的整个页面布局,我们需要在模板目录中创建一个 layout.kt 文件:
cox@CoxStation:~/go_wiki/src/go_wiki$ mkdir templates
cox@CoxStation:~/go_wiki/src/go_wiki$ emacs templates/layout.kt它的内容为:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" />
<title>MySQL数据库驱动的基于Go的维基系统</title>
<link href="/style.css" type="text/css" rel="stylesheet" />
</head>
<body>
<div>
<h1>MySQL数据库驱动的基于Go的维基系统</h1>
<div>
<div>$left.Render(Left)</div>
<div>$right.Render(Right)</div>
</div>
</div>
</body>
</html>上面这个简单布局的职责是:
- 创建基础的HTML文档结构,包括 doctype 、 head 、 body 等
- 渲染 left 与 right 两个分栏的具体内容,使用的数据是由 Left 与 Right 提供的
Render 方法是由 kview 包提供的,它能在特定的调用它的位置根据提供给它的数据渲染出子视图,这样的子视图可以有它自己的布局、div元素等等,并且子视图中还可以其自己的子视图(但是对于我们现在的这个小项目来说是完全没有必要的了)。
下一步,我们创建 list.kt ,它将被渲染到 left 中,它的内容是:
<a href="/edit/">创建新文章</a>
<hr />
<h2>最近更新</h2>
<ul>
$for _, article in Articles:
<li><a href="$article[Id]">$article[Title]</a></li>
$end
</ul>这个模板输出一个创建新文章*的链接以及一个文章标题链接列表。它使用到了一个 *for 声明用来遍历 Articles 列表(它是一个分片(slice)),之后的遍历得到的每一个项都使用 article[Id} 来创建与该文章对应的页面的URL地址,以及 article[Title] 来创建标题,Articles*、*Id*、以及*Title*都是 *ArticleList 类型中定义的成员(我们会在本文档的后面来定义它),*Id*与*Title*都将对应到*Row*片段中相应的记录,*article*将直接存储从数据库中取得的记录中的某一条。
for 声明在本地创建两个局部变量(_ 与 *article*),第一个是遍历次数,我们不需要它,所以直接将其丢掉,第二个就是从数据库取得的一条记录,对于那个遍历次数,虽然我们这里没有使用到它,但是它却很有用,比如下面这样的:
$for nn+, article in Articles:
<li>
<a href="$article[Id]">$article[Title]</a>
</li>
$end这会在每一个记录上面添加一个类,如果是第奇数条记录,则添加 *odd*,否则添加 *even*,我们这里使用 nn+ 是因为我们希望第一条记录在输入时, nn 不会 0,而是1。
现在来创建 show.kt 模板,它将被用来渲染文章数据:
<div>
$if Id:
<h2>$Title</h2>
<div>
$Body
</div>
<p>
<a href="/edit/$Id">编辑本文</a>
</p>
$else:
<h2>维其示例页面</h2>
<div>
<p>您现在所看到是本维基的示例页面,这说明您现在还没有指定任何内容。</p>
<p>本维基使用MySQl数据库存储数据,基于Go语言开发。</p>
<p>点击下方或者左侧的"创建新文章"链接以创建您的第一篇文章。</p>
<h3>本维其使用到的技术</h3>
<ul>
<li><a href='https://github.com/ziutek/kasia.go'>kasia.go</a></li>
<li><a href='https://github.com/ziutek/kview'>kview</a></li>
<li><a href='https://github.com/ziutek/mymysql'>MyMySQL</a></li>
</ul>
</div>
<p>
<a href="/edit/">创建新文章</a>
</p>
$end
</div>在这里你可以看到,我们使用了一个 *if-else*声明,如果我们指定了展示哪条文章数据了,那么就展示这些数据,如果没有的话,我们就展示一个默认的内容页(当然,这个内容页是无法让前端用户修改的)。
插一点有半 上下文堆栈 的知识
要使用 kview 包渲染某些模板,你需要用到两人个方法,在 Go 代码中的话,就是 *Exec*,在模板代码中的话,就是 *Render*,通常的你还需要给它们传递一些变量,比如像下面这样的:
v.Exec(wr, a, b)
v.Render(a, b)与视图 v 关联的模板将以下面这样的上下文堆栈渲染:
[]interface{}{globals, a, b}你可以看到,这里有一个 globals 变量,它是一个 *map*,包含了一些全局变量:
- 子视图(或者子模板)通过 Div 方法添加到视图 v 中
- len 以及 fmt 工具
- 你传递给 New 函数的变量也会被动态的添加到这些全局变量中
如果你想了解得更详细一些,可以看看 kview文档。
变量 b 处于这个堆栈的最底端,如果你在模板中这样写:
$x $@[1].y那么 Exec 或者 Render 方法将以下面这种方式去搜索 x 或者 y 属性:
- 首先在 b 中搜索 x*,如果没有找到,再在 *a 中搜索,如果还是没有找到,那么再去公用的全局变量中搜索。
- y 将只会在 a 中进行搜索,因为你已经直接指定了要在当前堆栈的那一个元素中去搜索(*@[1]y*)。
在上面的示例中,符号 @ 表示堆栈自向,所以,你可以像下面这样的写:
- Go代码: v.Exec(os.Stdout, “Hello”, “World!”, map[string]string{“cox”: “Antu”})
- 模板中: $@[1] $@[2] $@[1] $@ $cox!
- 输出: Hello World! Hello Antu!
最后,你还可以像下面这样输出整个堆栈以查看它的所有内容:
$for i, v in @:
$i: $v<br />
$end想了解更多请移步Kasia.go文档。
插了这点小知识之后,我们该回到前面一直在进行中的项目了,让我们来创建最后一个模板 edit.kt文件:
<form action="/$Id" method="post">
<h2>
<input type="text" name="title" id="title" value="$Title" placeholder="标题:$Title"/>
</h2>
<div>
<textarea name="body" id="body" placehoder="内容:$Body">$Body</textarea>
</div>
<div>
<input type="submit" value="退出" />
<input type="submit" name="submit" value="保存" />
</div>
</form>我们现在需要一个样式表来让这个维基好看一些,当然这不是必须的,你可以直接使用我下面的这一份样式表:
body {
font: 16px/1.62 "Xin Gothic", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", Arial, sans-serif;
color: #333;
margin: 0;
}
h1, h2, h3, h4, h5, h6, strong, em {
font-family: "Xin Gothic", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", Arial, sans-serif;
}
h1 {
margin: 0;
padding: .5em;
background: #ddd;
border-bottom: .1em solid #aaa;
}
h1 a {
text-decoration: none;
color: #333;
}
h2 {
margin: 0;
padding: .5em;
}
h2 input {
border: .1em solid #aaa;
font-size: 1em;
width: 80%;
}
div.field {padding: 1em}
div.field label {
font-size: 1.5em;
display: block;
}
textarea {
width: 90%;
border: .2em solid #aaa;
font-size: 1.2em;
line-height: 1.5em;
height: 10em;
}
.columns {
letter-spacing: -.45em;
}
.columns .left, .columns .right {
display: inline-block;
letter-spacing: normal;
min-height: 20em;
vertical-align: top;
}
.columns .left {
width: 30%;
border-right: .2em solid #aaa;
}
.columns .right {
width: 69%;
border-left: .2em solid #aaa;
}
.content {
padding: .5em 1em;
}
.button {
display: inline-block;
border: .1em solid #ddd;
background: #eee;
border-radius: .4em;
padding: .5em 1em;
margin: .5em;
color: #333;
text-decoration:none;
}
.button:hover {
background: #999;
}
.left a.button {
width: 70%;
text-align: center;
}
.list {
list-style: none;
padding: 0 .8em;
}
.list a {
display: inline-block;
text-decoration: none;
color: #333;
}连接到 MySQl 数据库服务器
我们使用 MyMySQL 包来连接 MySQl 数据库,先安装它:
cox@CoxStation:~/go_wiki$ go get github.com/ziutek/mymysql/autorc现在我们可以为我们的应用写 MySQl 连接器了,创建一个 mysql.go 文件,在该文件的第一部分我们会导入一些必须的包,定义一些常量和全局变量:
/*
维基的MySQl操作器
*/
package main
import (
"os"
"log"
"github.com/ziutek/mymysql/mysql"
"github.com/ziutek/mymysql/autorc"
_ "github.com/ziutek/mymysql/thrsafe"
)
const (
db_proto = "tcp"
db_addr = "127.0.0.1:3306"
db_user = "go_wiki"
db_pass = "go_wiki"
db_name = "go_wiki"
)
var (
// MySQl 连接处理器
db = autorc.New(db_proto, "", db_addr, db_user, db_pass, db_name)
// 预备声明
artlist_stmt, article_stmt, update_stmt *autorc.Stmt
)声明之后,MySQL 连接处理器已经可以连接到数据库了,但是我们并不会明显的去连接它。
在我们的应用中,我们将使用 MyMySQl 的 autorecon 接口,这是一些不需要连接数据库即可使用的函数集,更重要的是,使用它们,我们将不需要在因为网络原因或者数据库服务器重启导致与数据库连接中断之后重新手动再次连接数据库,它们会帮我们做好这些事情。
下一步我们定义一些 MySQL 错误处理程序:
func mysqlError(err error) (ret bool) {
ret = (err != nil)
if ret {
log.Println("MySQL error:", err)
}
return
}
func mysqlErrExit(err error) {
if mysqlError(err) {
os.Exit(1)
}
}接着再来定义初始化函数:
func init() {
var err error
// 初始化命令
db.Raw.Register("SET NAMES utf8")
// 准备好服务器商的声明
artlist_stmt, err = db.Prepare("SELECT id, title FROM articles")
mysqlErrExit(err)
article_stmt, err = db.Prepare(
"SELECT title, body FROM articles WHERE id = ?",
)
mysqlErrExit(err)
update_stmt, err = db.Prepare(
"INSERT articles (id, title, body) VALUES (?, ?, ?)" +
" ON DUPLICATE KEY UPDATE title=VALUES(title), body=VALUES(body)",
)
mysqlErrExit(err)
}Register 方法所注册的命令将在数据库连接创建之后立马执行, Prepare 方法则准备好服务器端的声明,因为我们使用了 mymysql/autorc 包,所以,当我们在准备第一个服务器端声明时,数据库连接就会被创建。
我们使用 预先声明 来代替普通的数据库查询的原因是这样做更加的安全,现在我们不再需要任何的其它函数来过滤用户输入的数据,因为SQL的逻辑与数据已经被完全分离开了,如果不这样做,我们总是很容易被别人进行数据库注入攻击。
下面让我们来创建从数据库中获取数据提供给页面使用的代码:
type ArticleList struct {
Id, Title int
Articles []mysql.Row
}
// 返回文章数据列表给 list.kt 模板使用,我们不使用 map 是因为那需要
// 做太多的事情,你或许在以后的项目中应该这么做,但是在这里,为了简单,
// 我们直接提供原始的 query 结果集以及索引给 id 和 title 字段。
func getArticleList() *ArticleList {
rows, res, err := artlist_stmt.Exec()
if mysqlError(err) {
return nil
}
return &ArticleList{
Id: res.Map("id"),
Title: res.Map("title"),
Articles: rows,
}
}再定义函数用来获取或者更新文章数据:
type Article struct {
Id int
Title, Body string
}
// 获取一篇文章
func getArticle(id int) (article *Article) {
rows, res, err := article_stmt.Exec(id)
if mysqlError(err) {
return
}
if len(rows) != 0 {
article = &Article{
Id: id,
Title: rows[0].Str(res.Map("title")),
Body: rows[0].Str(res.Map("body")),
}
}
return
}
// 插入或者更新一篇文章,它返回被更新/新插入的文章记录的id
func updateArticle(id int, title, body string) int {
_, res, err := update_stmt.Exec(id, title, body)
if mysqlError(err) {
return 0
}
return int(res.InsertId())
}最后的那个函数使用了 MySQL INSERT … ON DUPLICATE KEY UPDATE 查询,它的功能是 如果ID存在则更新,否则就插入新数据。
控制器
程序的最后一步就是创建一个控制器来与用户进行互动了,让我们创建 controller.go 文件:
package main
import (
"log"
"net/http"
"strconv"
"strings"
)
type ViewCtx struct {
Left, Right interface{}
}
// 渲染主页
func show(wr http.ResponseWriter, art_num string) {
id, _ := strconv.Atoi(art_num)
main_view.Exec(wr, ViewCtx{getArticleList(), getArticle(id)})
}
// 渲染编辑页面
func edit(wr http.ResponseWriter, art_num string) {
id, _ := strconv.Atoi(art_num)
edit_view.Exec(wr, ViewCtx{getArticleList(), getArticle(id)})
}
// 更新数据库以及渲染主页
func update(wr http.ResponseWriter, req *http.Request, art_num string) {
if req.FormValue("submit") == "保存" {
id, _ := strconv.Atoi(art_num) // id == 0 表示创建新文章
id = updateArticle(
id, req.FormValue("title"), req.FormValue("body"),
)
// 如果我们插入一篇瓣文章,我们就修改 art_num 为新插入文章的 id
// 这使得我们可以在成功插入新数据之后立马展示该条数据
art_num = strconv.Itoa(id)
}
// 重定身至主页面并展示新插入的文章
http.Redirect(wr, req, "/"+art_num, 303)
// 我们可以直接使用 show(wr, art_num) 展示新插入的文章
// 但是请查阅:http://en.wikipedia.org/wiki/Post/Redirect/Get
}
// 根据客户请求的方式以及URL地址来选择使用哪个控制器来处理
func router(wr http.ResponseWriter, req *http.Request) {
root_path := "/"
edit_path := "/edit/"
switch req.Method {
case "GET":
switch {
case req.URL.Path == "/style.css" || req.URL.Path == "/favicon.ico":
http.ServeFile(wr, req, "static"+req.URL.Path)
case strings.HasPrefix(req.URL.Path, edit_path):
edit(wr, req.URL.Path[len(edit_path):])
case strings.HasPrefix(req.URL.Path, root_path):
show(wr, req.URL.Path[len(root_path):])
}
case "POST":
switch {
case strings.HasPrefix(req.URL.Path, root_path):
update(wr, req, req.URL.Path[len(root_path):])
}
}
}
func main() {
err := http.ListenAndServe(":2223", http.HandlerFunc(router))
if err != nil {
log.Fatalln("ListenAndServe:", err)
}
}在上面的代码中:
- show 绑定了 GET 方法以及 /(.)* 这个URL结构,它被用来展示主页视图以及展示用户选择查看的文章。
- edit 绑定了 GET 方法以及 /edit/(.)* URL 结构,它负责处理渲染编辑页面
- update 绑定了 POST 方法以及 /(.)* URL结构,它负责更新文章数据到数据库,只有当用户点击了“ 保存 ”按钮才更新数据,如果点击的是 取消 那么直接不进行任何处理,当更新完成之后,将页面重定向至刚才更新的文章的展示页面。
运行我们的应用
cox@CoxStation:~/go_wiki/src/go_wiki$ go run *.go上面这行命令就可以运行我们的应用了,我们可以创建一个 Bash 脚本来启动我们的应用:
Ccox@CoxStation:~/go_wiki/src/go_wiki$ emacs run.sh其内容为:
go run *.go之后为其添加可执行权限,再运行它即可启动我们的应用:
cox@CoxStation:~/go_wiki/src/go_wiki$ chmod +x run.sh
cox@CoxStation:~/go_wiki/src/go_wiki$ ./run.sh从 controlle.go 代码中可以知道,我们的应用监听的是 2223 端口,打开浏览器,地址栏中输入:http://127.0.0.1:2223 即可访问到我们的应用。:
获取该示例的代码
你可以通过下面的命令获取到该示例的英文原版:
git clone git://github.com/ziutek/simple_go_wiki.git或者直接将其安装到你当前环境下 $GOPATH 所指定的工作空间中:
go get github.com/ziutek/simple_go_wiki如果你对我的翻译版本(与原版有些话不同)感兴趣的话,可以使用下面的地址下载:
- https://github.com/pantao/example-go-wiki/archive/master.zip
- 直接使用 Go 获取
go get github.com/pantao/example-go-wiki
其它框架
本示例中使用的是 http 完成的 controller,你还可以使用如 web.go 或者 twister 来重新实现。
使用 Markdown 格式化文章内容
我们的示例现在的文章内容是直接从数据库中读取的没有任何格式的纯文本,这在网页中显示出来之后就是一大段连续的没有分段分行的纯文本,很不符合我们的阅读,尤其是像本文这种需要清晰的格式化与条理的文章更加无法阅读了,所以,我们还可以选择一些文本格式化工具,比如我一直使用的 Markdown ,这需要你安装 markdown package 。
要在我们的项目中使用 Markdown,首先安装 Markdown 包:
cox@CoxStation:~/go_wiki$ go get github.com/knieriem/markdown然后还需要修改两人个文件 view.go 以及 show.kt :
在 view.go 中,做下面这样的修改:
import "github.com/ziutek/kview"改为:
import (
"bufio"
"bytes"
"github.com/ziutek/kview"
"github.com/knieriem/markdown"
)然后添加工具函数:
var (
mde = markdown.Extensions{
Smart: true,
Dlists: true,
FilterHTML: true,
FilterStyles: true,
}
utils = map[string]interface{} {
"markdown": func(txt string) []byte {
p := markdown.NewParser(&mde)
var buf bytes.Buffer
w := bufio.NewWriter(&buf)
r := bytes.NewBufferString(txt)
p.Markdown(r, markdown.ToHTML(w))
w.Flush()
return buf.Bytes()
},
}
)再将它添加到 show.kt 的全局变量中去:
main_view.Div("right", kview.New("show.kt", utils))最后我们需要在 show.kt 文件中将 $Body 修改为 $:markdown(Body) 即可。
应用运行截图
 Golang Wiki 编辑页
Golang Wiki 编辑页
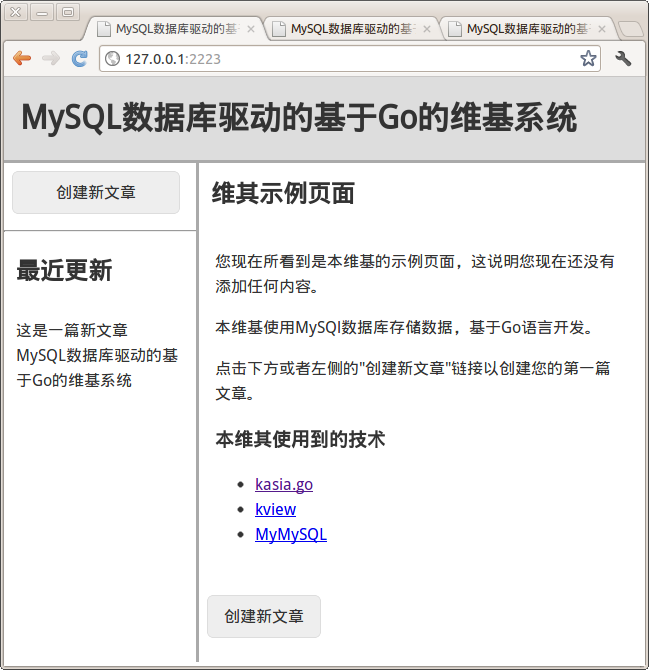 Golang Wiki 前端阅读页
Golang Wiki 前端阅读页
Go 模板集
模板集是Go中一种特殊的数据类型,它允许你将若干有关联性的模板归为一个组,当然了,它不是一个个体的数据类型,而是被归入了模板的数据结构中。所以,如果你在一些文件中使用了{{define}}…{{end}} 声明,那么这一块就成为了一个模板。
比如一个网页,有头部(Header),主体(Body)以及页脚(Footer),那么这些区域我们都可以在一个文件中定义为一个一个的模板,它们将可以通过一次请求读取到你的程序中,例如:
{{define "header"}}
<html>
<head></head>
{{end}}
{{define "body"}}
<body></body>
{{end}}
{{define "footer"}}
</html>
{{end}}这里的关键知识是:
- 每一个模板都是由 {{define}}…{{end}} 对定义的
- 每一个模板都给定了一个唯一的名称——如果你在一个文件中定义重复使用一个名称将引起一个 Panic
- 不允许将任何字符写在 {{define}}…{{end}}对外——否则会引起Panic
这上面这样的文件被解析为一个模板集之后,Go自动的创建一个以模板名称为键,模板内容为值的 Map:
tmplVar["header"] = pointer to parsed template of text "<html> … </head>"
tmplVar["body"] = pointer to parsed template of text "<body> … </body>"
tmplVar["footer"] = pointer to parsed template of text "</html>"同一个模板集中的模板是知道有其它模板存在的,所以如果有一个模板是可以在各个其它模板中调用的,那么你需要将这个模板单独保存为一个文件,然后再在需要的地方调用它。
现在我们来使用一个简单的示例更好的说明这一切:
- 定义一个模板——使用 {{define}}…{{end}}
- 在一个模板中引入另一个模板——使用 {{template “template name”“}}
- 解析多个文件成为一个模板集——使用 template.ParseFiles
- 执行或者转换模板——使用 template.ExecuteTemplate
先创建两人个模板文件:
- 模板文件一:t1.tmpl
{{define "t_ab"}}a b{{template "t_cd"}}e f {{end}}
上面这个文件将被解析为名为 t_ab 的模板,它还引入了一个名为 t_cd 的模板 - 模板文件二:t2.tmpl
{{define "t_cd"}} c d {{end}}
上面这个文件将被解析为 t_cd 模板
程序代码:
package main
import (
"text/template"
"os"
"fmt"
)
func main() {
fmt.Println("Load a set of templates with {{define}} clauses and execute:")
s1, _ := template.ParseFiles("t1.tmpl", "t2.tmpl") //create a set of templates from many files.
//Note that t1.tmpl is the file with contents "{{define "t_ab"}}a b{{template "t_cd"}}e f {{end}}"
//Note that t2.tmpl is the file with contents "{{define "t_cd"}} c d {{end}}"
s1.ExecuteTemplate(os.Stdout, "t_cd", nil) //just printing of c d
fmt.Println()
s1.ExecuteTemplate(os.Stdout, "t_ab", nil) //execute t_ab which will include t_cd
fmt.Println()
s1.Execute(os.Stdout, nil) //since templates in this data structure are named, there is no default template and so it prints nothing
}输出结果为:
c d
a b c d e ftemplate.ParseGlob 与 template.ParseFiles 类似,只是它只需要接收一个通配符*作为参数,比如上面的这个示例,你可以使用 *template.ParseGlob("t.tmpl”)*也可以得到同样的结果。
Go 模板——结构与数据控制
http://golang.org/pkg/text/template/ 与 http://golang.org/pkg/html/template/ 是Go官方的关于 *template*包的文档,——html子包提供了一些附加的安装相关的功能,比如防止代码注入的功能经常在我们的网络编程中被使用。
管道(Pipeline)
Unix 用户肯定是明白什么是 Piping 数据,很多程序都提供字符输出——一个字条流,比如你在终端中键入 ls 命令,你将得到一个包含所有当前目录文件名称的列表,它可以被翻译为:“获取当前目录中所有文件名称的列表,然后通过管道将其传送到标准输出,而当前标准输出为命令行终端的屏幕”。
在Unix命令行终端中,管道“*|*”就可以将你一个命令的输入传送给另一个命令,比如:
cox@Cox:~$ ls | grep "a"
access_log
examples.desktop
goworkspace
VirtualBox VMs
workspace上面的命令 ls 首先获取当前目录下所有文件的列表,然后再通过管道传递给 grep 命令,grep 从里面搜索包含字符“a”的条目,然后再将过滤后的结果通过管道传递给标准输出,标准输出打印出所有结果,如果你还想再过滤,还可以这样:
cox@Cox:~$ ls | grep "a" | grep "V"
VirtualBox VMs在Go中,我们也可以将任何一个像上面这样的字符流称之为管道,它们同样可以通过管道传送给其它命令,在下面的示例中,处于 {{ }} 中间的字符串与外面的字符串是不一样的——这些静态文本被无修改的复制到外面。
package main
import (
"text/template"
"os"
)
func main() {
t := template.New("Template Test")
t = template.Must(t.Parse("This is just static text. n{{"This is pipeline data - because it is evaluated within the double braces."}} {{ `So is this, but within reverse quotes.`}}n"))
t.Execute(os.Stdout, nil)
}输出为:
This is just static text.
This is pipeline data - because it is evaluated within the double braces. So is this, but within reverse quotes.模板中的 if-else-end
在模板中使用 if-else 控制结构与在普通代码中使用差不多,在Go模板中,如果传送数据到if的管道为空,则等同为 false:
package main
import (
"os"
"text/template"
)
func main() {
tEmpty := template.New("template test")
tEmpty = template.Must(tEmpty.Parse("Empty pipeline if demo: {{if ``}} Will not print. {{ end}}n"))
tEmpty.Execute(os.Stdout, nil)
tWithValue := template.New("template test")
tWithValue = template.Must(tWithValue.Parse("Non empty pipline if demo: {{if `anything`}} Print If Part.{{ end}}n"))
tWithValue.Execute(os.Stdout, nil)
tIfElse := template.New("template test")
tIfElse = template.Must(tIfElse.Parse("If-else demo:{{if `anything`}} Print IF Part. {{ else }} Else part. {{end}}n"))
tIfElse.Execute(os.Stdout, nil)
}输出为:
Empty pipeline if demo:
Non empty pipline if demo: Print If Part.
If-else demo: Print IF Part.点(*.*)
在Go模板中,点(.)被用来引用当前的管道,你可以想像成为这个点是 Java 中的 this 或者我们在Python中最常使用的 *self*,你可以使用 *{{.}}*引用到它的值。
with-end 结构
with 声明用来设置 点(.) 在管道中的数据:
package main
import (
"os"
"text/template"
)
func main() {
t, _ := template.New("test").Parse("{{with `hello`}}{{.}}{{end}}!n")
t.Execute(os.Stdout, nil)
t1, _ := template.New("test").Parse("{{with `hello`}}{{.}} {{with `Mary`}}{{.}}{{end}}{{end}}!n") //when nested, the dot takes the value according to closest scope.
t1.Execute(os.Stdout, nil)
}输出为:
hello!
hello Mary!模板变量
你可以在模板管道中使用*$*前缀创建本地变量,变量名称必须为英文字母、数字以及下划线:
package main
import (
"os"
"text/template"
)
func main() {
t := template.Must(template.New("name").Parse("{{with $3 := `hello`}}{{$3}}{{end}}!n"))
t.Execute(os.Stdout, nil)
t1 := template.Must(template.New("name1").Parse("{{with $x3 := `hola`}}{{$x3}}{{end}}!n"))
t1.Execute(os.Stdout, nil)
t2 := template.Must(template.New("name2").Parse("{{with $x_1 := `hey`}}{{$x_1}} {{.}} {{$x_1}}{{end}}!n"))
t2.Execute(os.Stdout, nil)
}被重新定义的函数
Go模板同样还提供了一些被重新定义了的函数,比如下面这个示例的 printf 就与 fmt.Sprintf 类似:
package main
import (
"os"
"text/template"
)
func main() {
t := template.New("test")
t = template.Must(t.Parse("{{with $x := `hello`}}{{printf `%s %s` $x `Mary`}}{{end}}!n"))
t.Execute(os.Stdout, nil)
}输出为:
hello Mary!Go 模板
网络服务总是以HTML网页或者数据的形式回复客户的请求,这通常都带有很多的内容,这包括用户所请求的数据或者HTML结构,使用模板能让我们更方便的将普通的纯文本内容转换为有着特殊格式的文本,比如下面这种情况:
Template:
+---------------+
| Hello, {NAME} |-----+
+---------------+ | +-------------+
Data: +---> + Hello, Mary |
+---------------+ | +-------------+
| NAME = "Mary" |-----+
+---------------+在Go中,我们使用 *templates*包中的如 *Parse*、*ParseFile*、*Execute*等方法从一段字符串或者一个模板文件加载模板然后转换为输出,这些用来添加到模板中的数据一些都保存在某个可以被导入的类型字段中,比如上面这个示例可以是这样的实现:
+--------------------+
|template: |
|"Hello, {NAME}" |-----+
+--------------------+ -------+ +-------------+
template.Execute() +---> + Hello, Mary |
+--------------------+ /-------+ +-------------+
|type struct: |-----+
|Person{NAME:"Mary"} |
+--------------------+最典型的使用方法是为网页生成HTML代码的文件,我们需要选择打开一个已经定义好报模板文件,然后使用*template.Execute*方法将一些数据填充到模板文件中,接着使用 *http.ResponseWriter*将结果发入到返回给客户端的数据流。
func handler(w http.ResponseWriter, r *http.Request) {
t := template.New("some template") // 创建一个新的 template
t, _ = t.ParseFiles("tmpl/welcome.html", nil) // 从文本文件打开并分析一个模板
user := GetCurrentlyLoggedInUser() // 一个用来获取当前登陆用户信息的文法
t.Execute(w, User)
}- 对于你真实的网站开始,你可能需要使用 *template.ParseFiles*,但是在这里,我们做为示例,就不再单独写一个模板文件了,而是直接使用 *template.Parse*,它与前者有一样的功能,只是它不是从一个文件中读取模板,而是直接从一个字符串中创建模板。
- 我们不将示例写作一个Web服务,而是直接将结果打开到我们的命令行终端中。这便得我们需要使用 *io.Stdout*,它关联到我们的标准输出——os.Stdout实现了io.Writer接口。
字段替换——{{.FieldName}}
要在模板文件中输出字段一数据,只需要在该字段名称前面加一个小数点“.*”,然后再将其放入一个双层的大括号“{{}}”里面即可,比如我们需要输出的字段为 *Name*,那么就只需要把 *{{.Name}} 放在模板文件的合适的位置即可。
package main
import (
"os"
"text/template"
)
type Person struct {
Name string // 可导出的字段
}
func main() {
t := template.New("Hello Template") // 创建一个名为 Hello Template 的模板
t, _ = t.Parse("Hello {{.Name}}") // 分析模板并创建一个模板
p := Person{Name:"Mary"} // 定义一个实例
t.Execute(os.Stdout, p) // 转换模板t,填充了p中的数据
}输出为:
Hello Mary为了完整演示,我在这模板里面添加一个不存在的字段nonExportedAgeField*,它是以小写字母开头的,所以未导出,这会导致一个错误,你可以从 *Execute 方法的返回结果中获取到错误信息。
package main
import (
"os"
"text/template"
"fmt"
)
type Person struct {
Name string
nonExportedAgeField string
}
func main() {
p := Person{Name: "Mary", nonExportedAgeField: "44"}
t := template.New("nonexported template demo")
t, _ = t.Parse("Hello {{.Name}}! Age is {{.nonExportedAgeField}}.")
err := t.Execute(os.Stdout, p)
if err != nil {
fmt.Println("There was an error:", err)
}
}输出为:
Hello Mary! Age is There was an error: template: nonexported template demo:1: can't evaluate field nonExportedAgeField in type main.Persontemplate.Must函数——检测模板是否正确
template中的静态函数 *Must*可以检测模板是否正确,比如标签是否都已经关闭或者变量是否都是可输出的等等:
package main
import (
"text/template"
"fmt"
)
func main() {
tOk := template.New("first")
template.Must(tOk.Parse(" some static text /* and a comment */")) //a valid template, so no panic with Must
fmt.Println("The first one parsed OK.")
template.Must(template.New("second").Parse("some static text {{ .Name }}"))
fmt.Println("The second one parsed OK.")
fmt.Println("The next one ought to fail.")
tErr := template.New("check parse error with Must")
template.Must(tErr.Parse(" some static text {{ .Name }")) // due to unmatched brace, there should be a panic here
}输出为:
The first one parsed OK.
The second one parsed OK.
The next one ought to fail.
panic: template: check parse error with Must:1: unexpected "}" in command
goroutine 1 [running]:
text/template.Must(0x0, 0xf840031030, 0xf840034380, 0x0, 0xf840031030, ...)
/usr/lib/go/src/pkg/text/template/helper.go:23 +0x4e
main.main()
/home/cox/workspace/go/src/gotutorial/templates3.go:18 +0x39d
goroutine 2 [syscall]:
created by runtime.main
/build/buildd/golang-1/src/pkg/runtime/proc.c:221
exit status 2